



Опубликован драфт (насколько я помню в открытом доступе его ранее не было) ред-бука, посвященного новой midrange системе хранения и “виртуализатору” в одном лице – IBM V7000. Вопросов про нее задают довольно много, поэтому книжка вероятно будет пользоваться популярностью. Рассказывается там буквально про все – начиная от формальных маркетинговых характеристик и заканчивая траблшутингом.
Читать дальше ...четверг, 23 декабря 2010 г.
четверг, 16 декабря 2010 г.
Планирование VMware High Availability
VMware на днях опубликовали краткий, но довольно полезный документ про то как нужно планировать HA: “VMware High Availability (HA): Deployment Best Practices”. Хотя, по большому счету, никаких тайных знаний там не содержится, но прочитать хотя бы один раз настоятельно рекомендуется (особенно тем, кто только планирует развернуть у себя инфраструктуру).
Читать дальше ...понедельник, 13 декабря 2010 г.
Новые контроллеры Adaptec серии 6
Компания PMC-Sierra, впервые после приобретения Adaptec, анонсировала долгожданное продолжение линейки RAID-контроллеров! Объявлено о выпуске 6й серии: Adaptec RAID 6405, 6445 и 6805.

Контроллеры построены на базе чипа серии SRC 8x6G (dual core 600MHz PM8013) RoC (RAID-on-Chip). Все три новых контроллера имеют одинаковый функционал, а отличие только в портах: 6405 имеет 4 внутренних SAS порта, 6445 – 4 внутренних и 4 внешних, а 6805, как легко догадаться, – 8 внутренних портов. Для всех контроллеров вместо батарейки предлагается использовать флэш-память, защищаемую конденсаторами (Adaptec Flash Module 600 - AFM 600). Остальные характеристики:
- 512МБ кэш памяти (DDR2-667)
- поддержка SAS 2.0 (6Gbps)
- шина PCIe Gen2 x8
- поддержка до 256 дисков SAS/SATA (при использовании экспандеров)
- поддержка уровней RAID 0, 1, 1E, 5, 5EE, 6, 10, 50, 60 и JBOD
- возможность использования Hybrid RAID (SSD + HDD)
Как и для прошлых серий, управление осуществляется через Adaptec Storage Manager – это может быть очень важно для тех, кто уже активно использует контроллеры Adaptec в своих серверах, но посматривали “на сторону” в поисках продуктов с поддержкой 6Gbps.
Про поддержку технологии maxCache в новых контроллерах у меня однозначного ответа пока нет – нужно будет отдельно уточнить.
Более подробная информация должна быть через несколько дней.
Читать дальше ...
вторник, 9 ноября 2010 г.
NVIDIA Tesla в blade
IBM анонсировал специальное лезвие с NVIDIA Tesla внутри - BladeCenter GPU Expansion Blade. Вернее это даже не лезвие, а дополнительный модуль, который подключается к стандартному лезвию (на текущий момент поддерживается только HS22). Внутри установлена одна плата NVIDIA Tesla M2070 или M2070Q:
Благодаря возможности стекирования, к одному лезвию HS22 можно подключить до 3х модулей с теслами. Тем самым, в одно шасси можно уставить до 10ти тесл и получить в свое распоряжение почти 4.5 тысячи ядер и 5Tflops. В случае необходимости использовать CFFh карту расширения, она должна быть поставлена в самый “верхний” модуль GPU Extension.
Модули GPU Extension поддерживаются в шасси BC-E (только с блоками 2320W), BC-H и BC-HT. Отгрузки начнутся в середине декабря.
Читать дальше ...вторник, 26 октября 2010 г.
Защита от спама, вирусов и web-атак? Легко!
Какие задачи в плане ИТ стоят практически перед 100% компаний?
- Безопасный доступ в интернет
- Почта без вирусов и спама
Решение этих двух проблем в большинстве случаев требует не только усилий системного администратора, но и расходов на дополнительное оборудование и ПО: покупка и настройка почтового сервера; покупка и настройка антиспама; покупка и настройка антивируса; покупка и настройка ПО для фильтрации Web-трафика.
Начальная настройка не является единственным требованием - необходимо еще и поддерживать систему в актуальном состоянии - каждый день появляются новые типы атак и вирусов, спам рассылки также не стоят на месте. И если не уделять должное внимание системе, очень скоро она практически перестанет выполнять возложенные на нее функции.
Но зачастую администраторы ограничиваются настройкой почтового сервера внутри организации, а остальные вопросы решаются лишь частично - спам и вирусы "отлавливаются" на уровне рабочих мест, а если и централизованно, то все равно "внутри" сети. Из-за этого растут и расходы на трафик, и требования к вычислительным мощностям, необходимым для защиты инфраструктуры.
А ведь именно через web-ресурсы сейчас происходит распространение угроз и защита от них становится все более актуальной. Компаниям приходится, с одной стороны, защищаться от этих угроз, а с другой стороны, находить способы сокращения расходов на IT, увеличения продуктивности и упрощения сетей передачи данных.
Еще одна важная проблема, стоящая при построении IT-инфраструктуры - обеспечение отказоустойчивости. Необходимо не только настроить ПО и оборудование, но и снизить время простоя в случае возникновения каких-либо проблем как с "железом", так и с "софтом".
Решением всех этих проблем может стать использование облачных сервисов Zscaler!
Весь интернет-трафик перенаправляется через облако Zscaler. Фактически, Zscaler играет роль удаленного proxy-сервера. Облако обеспечит защиту от вирусов, шпионского ПО, ботнетов и тысячи усовершенствованных веб-угроз. Облако обеспечивает также полный перечень возможностей по URL-фильтрации. Нежелательные URL-адреса могут быть заблокированы, а работа прошедших фильтрацию категорий проконтролирована. Результаты общего мониторинга использования интернета могут быть зафиксированы на несложном в управлении облачном отчетном портале.
Технология Nanolog позволяет в реальном времени осуществлять анализ и контроль всей веб-активности. Централизованная отчетность позволяет упростить администрирование и сократить для организации операционные расходы на IT. Информация об активности пользователей попадает в отчеты практически мгновенно.

Через облако Zscaler перенаправляется и весь трафик электронной почты. Облако обеспечит защиту от вирусов, шпионского ПО и спама. Решение дает возможность повысить контроль потока почты и степень шифрования. Помимо этого, его использование поможет выявить и предотвратить преднамеренную или непреднамеренную утечку данных посредством электронной почты. Ограниченные в ресурсах небольшие компании могут значительно выиграть, получив сервис, более простой в управлении, и главное, значительно более экономичный. Единственное что требуется - изменить запись MX в DNS так, чтобы почтовый трафик был направлен на серверы Zscaler.

Никакого дополнительного программного или аппаратного обеспечения не требуется. "Подозрительные" сообщения остаются в облаке и, в случае ложного срабатывания, их конечно можно получить - никакие важные сообщения не будут потеряны.
Не только небольшие, но и крупные компании могут эффективно использовать сервисы Zscaler. Благодаря Zscaler, компания может защищать свои удаленные офисы, без установки дополнительного оборудования. Контроль трафика осуществляется глобально и корпоративная политика соблюдается пользователями независимо от их местоположения - в офисе, дома или в интернет-кафе.
Задача высокой доступности в Zscaler решена на уровне архитектуры системы - каждый узел (Zscaler Enforcement Node) всех дата-центров имеет многократный уровень дублирования, что гарантирует постоянную доступность облака. В случае отказа узла, трафик может быть перенаправлен на любой другой узел глобальной сети, благодаря чему достигается высокая доступность, не зависящая от локальных проблем, таких как природные катаклизмы.
Интеграция с Active Directory и службами LDAP обеспечивает простое управления пользователями и доступом к ресурсам.
Самое главное, в отличие от большинства других продуктов, попробовать Zscaler очень просто! Всего за 4 часа можно оценить преимущества и возможности решения. Куда обращаться? Конечно к нам!
среда, 20 октября 2010 г.
IBM: еще один тяжеловес с SAS дисками
Возвращаюсь к уже сделанным анонсам – IBM, вслед за HDS, выпустили продолжение для своей линейки DS8000. Как и ожидалось, из DS8700 название системы превратилась в DS8800. Аппаратных новшеств в системе много – надо же чем-то крыть конкурентов. Впрочем, IBM традиционно сохраняет преемственность кода в своих “восьмитысячниках”, поэтому непосредственным изменениям программной части подверглось (как утверждается) не более 15% от общего объема.


Еще одно из важных изменений – теперь охлаждение реализовано стандартно – с фронта забираем холодный воздух, назад – горячий. Ранее горячий воздух выходил сверху, а забирался и спереди, и сзади, что создавало определенные сложности в проектировании.
С выпуском явно торопились – многие возможности из DS8700 перенести к анонсу не успели (скорее всего перенести-то успели, но вот оттестировать нормально – нет), поэтому если хочется использовать например Easy Tier, Remote Pair FlashCopy, Quick initialization и thin provisioning, 16 TB LUN, то нужно ждать первого квартала 2011 года. К этому моменту IBM обещает все сделать.
Читать дальше ...четверг, 14 октября 2010 г.
VMware SRM – снижаем требования к полосе пропускания
Случайно наткнулся на интересную заметку в блоге Dave Lawrence про то как лучше настроить VMware SRM, чтобы сократить требования к полосе пропускания между площадками. Вкратце: стоит ли настраивать репликацию дисков со swap-файлами? По логике конечно нет – раз уж даже в официальных документах VMware рекомендуется не реплицировать диски со swap файлами VM, то уж своп виртуальных машин точно не нужен. Известны случаи, когда в результате отказа от репликации файла подкачки, удавалось сократить трафик на 80%! Подробное описание можно найти вот в этом документе NetApp: VMware vCenter Site Recovery Manager in a NetApp Environment. Основная хитрость состоит в том чтобы на удаленной площадке для каждой VM оказался нереплицируемый диск с правильной сигнатурой (иначе при рестарте VM диск получит другую букву и мы столкнемся с очевидными проблемами).
Читать дальше ...понедельник, 11 октября 2010 г.
IBM: новые возможности и новые системы хранения
Уж не знаю чем так в IBM надоели вторничные анонсы, но похоже что теперь нам придется привыкать к новостям в четверг. В прошлый, например, было объявлено столько всего что теряюсь за что взяться вначале. Даже выстроить порядок по значимости довольно проблематично, поэтому пойду в случайном порядке :)
SAN Volume Controller (SVC) обновился до версии 6.1. Речь конечно идет не про железную часть SVC, а про программный код. Прежде всего, в новой версии будет доступна технология Easy Tier, которая уже некоторое время присутствует во флагмане – high end системе DS8700. Easy Tier автоматически размещает блоки данных, к которым доступ осуществляется наиболее частно, на более быстрых носителях (например, SSD дисках). Т.е. сам LUN может быть размещен частично на SSD, частично на SAS и частично на SATA дисках. Благодаря Easy Tier можно существенно повысить производительность дисковой системы без переноса всего LUN на более дорогие носители:
 Также добавилась поддержка VMware vSphere 4.1 и очередной порции дисковый систем как самой же IBM, так и от других компаний. Еще одно заметное изменение - радикально переделан пользовательский интерфейс. Хотя и старый был вполне логичен, но разобраться с ним было далеко не просто (особенно если до этого опыта работы с различными СХД было мало), но теперь внешний вид переняли у XIV. А надо заметить, что найти GUI проще и понятнее чем в XIV практически невозможно (на мой взгляд).
Также добавилась поддержка VMware vSphere 4.1 и очередной порции дисковый систем как самой же IBM, так и от других компаний. Еще одно заметное изменение - радикально переделан пользовательский интерфейс. Хотя и старый был вполне логичен, но разобраться с ним было далеко не просто (особенно если до этого опыта работы с различными СХД было мало), но теперь внешний вид переняли у XIV. А надо заметить, что найти GUI проще и понятнее чем в XIV практически невозможно (на мой взгляд).  Заодно с интерфейсом поменялись и некоторые термины. Вместо сложного “vDisk to host mapping” остался просто “Host mapping”, вместо “Space-efficient” – уже привычный всем “Thin provisioning”, вместо “Virtual Disk (VDisk)” – гораздо более привычный пользователям СХД “Volume”, ну а вместо “Managed Disk (MDisk) group” – “Storage pool”. Небольшой ложкой дегтя для пользователей SVC с внутренними дисками SSD (а такая возможность для узлов CF8 появилась почти год как тому назад) будет необходимость немного подождать – внутренние SSD не поддерживаются в релизе 6.1. Их поддержка вновь появится, но немного позднее. Впрочем, это не должно сказаться на основной массе установленных систем.
Заодно с интерфейсом поменялись и некоторые термины. Вместо сложного “vDisk to host mapping” остался просто “Host mapping”, вместо “Space-efficient” – уже привычный всем “Thin provisioning”, вместо “Virtual Disk (VDisk)” – гораздо более привычный пользователям СХД “Volume”, ну а вместо “Managed Disk (MDisk) group” – “Storage pool”. Небольшой ложкой дегтя для пользователей SVC с внутренними дисками SSD (а такая возможность для узлов CF8 появилась почти год как тому назад) будет необходимость немного подождать – внутренние SSD не поддерживаются в релизе 6.1. Их поддержка вновь появится, но немного позднее. Впрочем, это не должно сказаться на основной массе установленных систем.Storwize V7000. Вот и сказано новое слово в системах IBM класса midrange. Вопреки многим подозрениям не имеет никакого отношения к приобретенной ранее компании Storwize и ее продуктам по компрессии данных в реальном времени. Более того, чтобы избежать путаницы бывшие Storwize получат новые названия, так как Storwize больше, по мнению IBM, подходит для системы хранения. (Очень интересный подход к приобретению компании – с одной стороны, приобрели ради конкретных технологий и продуктов, а с другой – нашли удачное применение старому названию. Можно сказать двойная отдача :) ). Что же это за зверь такой – V7000? Система эта уже гораздо более IBM чем широко известные DS3000/DS5000/Nxxx (первые две это OEM LSI, а N-серия тоже “чужая” и является OEM-ом NetApp). До недавнего момента IBM мог похвастаться полностью своими системами только в верхнем сегменте – DS8000, XIV (которая правда разработана вне IBM и уже потом куплена ). Ну и еще есть конечно очень сильный продукт – SAN Volume Controller. Но SVC является в чистом виде “виртуализатором”, т.е. не содержит жестких дисков (есть маленькое исключение в виде SSD, но про него пока забудем) и занимается исключительно обработкой потоков данных между серверами и СХД. А что если совместить SVC и небольшую дисковую систему? Такое решение зрело уже давно и именно оно нашло воплощение в продукте под названием Storwize V7000, который является комбинацией возможностей SVC (по большей части) и DS8000 (довольно скромный вклад). Очень хорошая иллюстрация нашлась здесь:
 Зеленый цвет соответствует коду, привнесенному от SVC 5й версии; голубой – новые возможности, появившиеся и в SVC 6.1, и в V7000 (разумеется, всё что касается дисков и блоков питания относится только к V7000).
Зеленый цвет соответствует коду, привнесенному от SVC 5й версии; голубой – новые возможности, появившиеся и в SVC 6.1, и в V7000 (разумеется, всё что касается дисков и блоков питания относится только к V7000).Для новой системы сразу появляется два типичных сценария внедрения:
- новая система V7000 с относительно небольшим числом дисков и дальнейший рост за счет подключения внешних систем
- плановое вытеснение уже установленной СХД на второй план за счет виртуализации
В случае с обычной версией SVC, оба таких сценария потребуют покупки сразу двух продуктов – непосредственно SVC и дисковой системы. Такой подход далеко не всегда находит понимание в “высших” сферах. А теперь достаточно приобрести V7000 и можно будет как использовать ее внутренние диски, так и подключать внешние системы хранения.

Так что же представляет собой V7000? Как и в случае с DS3500, доступны два базовых варианта – 2U система с 12ю дисками 3.5’’ и 2U с 24мя дисками 2.5’’. Поддерживаются диски SSD, SAS, Near Line SAS. На текущий момент можно подключать до 120 дисков, но уже ко второму кварталу 2011г. обещают увеличить число поддерживаемых дисков вдвое – до 240. Полки расширения также двух типов – 2U 12x3.5’’ и 24x2.5’’, подключаются через SAS 6Gbit. Контроллерный модуль содержит два контроллера, по 8ГБ кэша в каждом (правда, правильнее будет наверное сказать не кэша, а памяти). Каждый контроллер имеет по 4 порта FC 8Gbit и по 2 порта iSCSI 1Gbit. Внешние дисковые системы (для последующей виртуализации) подключаются через FC порты, т.е. порты на контроллере в принципе идентичны имеющимся в узлах SVC CF8. “Железо”, как я подозреваю, выпускается тем же самым производителем, который делает модули для систем XIV. Подключение полок расширения делается несколько иначе чем в остальных системах IBM. Вместо ставшего привычным подключения “сверху-вниз, снизу-вверх”, в V7000 полки подключаются последовательно. С одной стороны, это гораздо проще, с другой – чуть опаснее, так как полный отказ полки “в середине” приведет к отказу всех следующих за ней дисков. Справедливости ради стоит отметить, что такой печальный вариант развития событий крайне маловероятен в силу отсутствия незадублированных активных компонентов внутри полки. Кроме того, большинство других производителей не стесняются использовать такой способ подключения в системах с гораздо большим числом дисков. Для “внутренних” дисков поддерживается RAID 0, 1, 5, 6 и 10. Остальные возможности пришли из SVC – это выделение дискового пространства по требованию (thin provisioning), зеркалирование виртуальных дисков (VDisk mirroring), поддержка FlashCopy и RemoteCopy. Как и в новой версии SVC 6.1, поддерживается технология Easy Tier. Добавив всего несколько SSD в конфигурацию V7000 можно радикально увеличить производительность системы. А благодаря возможностям виртуализации, благодаря Easy Tier можно увеличить производительность томов, которые сейчас размещены на уже имеющихся дисковых системах. Удивительная по удобству использования графическая оболочка в V7000 пришла из систем IBM XIV.
Про остальные анонсы наверное чуть позднее – и без того получился слишком длинный пост.
Читать дальше ...
пятница, 8 октября 2010 г.
«Универсальные серверы Supermicro. Высокое качество, надежность, производительность, низкая цена.
Уважаемые дамы и господа,
Приглашаем Вас и Ваших коллег на бесплатный практический семинар 26 октября 2010 года, который пройдет в Санкт-Петербурге в Гранд Отеле Европа. Семинар организуется совместно с ведущим производителем универсального серверного оборудования компанией Supermicro. Программа разработана для руководителей ИТ-подразделений, технических директоров, руководителей ИТ-служб, главных системных администраторов.
У Вас будет возможность:
• ознакомиться с практическим опытом использования многообразия серверных компонентов Supermicro;
• увидеть новые решения от Supermicro;
• получить бесплатную консультацию по работе с серверным оборудованием.
Наши специалисты уже 17 лет занимаются системной интеграцией, производством, обслуживанием и поставкой серверов.
В качестве бонуса для посетителей семинара мы предлагаем профессиональную консультацию по подбору серверного оборудования для решения ваших бизнес-задач.
Спасибо за ваше время и внимание! Пусть все ваши проекты будут успешными!
Регистрация ОБЯЗАТЕЛЬНА. Для регистрации Вам необходимо связаться с Ольгой Алексеевой o.alekseeva@trinitygroup.ru, +7(812) 327-59-60 или +7(921)-595-95-98.
Семинар рассчитан на 50 участников, мы ждем Ваших обращений и заявок на участие до 22 октября।
Читать дальше ...
Приглашаем Вас и Ваших коллег на бесплатный практический семинар 26 октября 2010 года, который пройдет в Санкт-Петербурге в Гранд Отеле Европа. Семинар организуется совместно с ведущим производителем универсального серверного оборудования компанией Supermicro. Программа разработана для руководителей ИТ-подразделений, технических директоров, руководителей ИТ-служб, главных системных администраторов.
У Вас будет возможность:
• ознакомиться с практическим опытом использования многообразия серверных компонентов Supermicro;
• увидеть новые решения от Supermicro;
• получить бесплатную консультацию по работе с серверным оборудованием.
Наши специалисты уже 17 лет занимаются системной интеграцией, производством, обслуживанием и поставкой серверов.
В качестве бонуса для посетителей семинара мы предлагаем профессиональную консультацию по подбору серверного оборудования для решения ваших бизнес-задач.
Спасибо за ваше время и внимание! Пусть все ваши проекты будут успешными!
Регистрация ОБЯЗАТЕЛЬНА. Для регистрации Вам необходимо связаться с Ольгой Алексеевой o.alekseeva@trinitygroup.ru, +7(812) 327-59-60 или +7(921)-595-95-98.
Семинар рассчитан на 50 участников, мы ждем Ваших обращений и заявок на участие до 22 октября।
Читать дальше ...
четверг, 7 октября 2010 г.
Семинар Тринити + Microsoft + Hyper-V
Мы рады пригласить Вас на семинар, проводимый компаниями Microsoft и Тринити, посвященный теме:
«Построение систем высокой доступности»
Одна из основных задач IT – это повышение доступности сервисов, которые предоставляются пользователям. Данный круглый стол посвящен теме построению систем высокой доступности с помощью технологий виртуализации компании Microsoft и ее партнеров. В рамках семинара будут рассмотрены как решения Microsoft, так и сторонние прикладные решения, расширяющие их функционал.
Мероприятие состоится 19 октября - (с 09:30-13:00) по адресу ул. Крылатская, д.17, корп. 1., бизнес центр «Крылатские холмы»
Программа:
09:30 – 10:00 Утренний кофе, регистрация
10:00 – 11:30 Как построить систему высокой доступности и нужна ли для этого виртуализация?
11:30 – 12:00 Перерыв на кофе
12:00 – 13:00 Средства повышения доступности приложений в виртуальной среде Microsoft Hyper-V
Будем рады видеть Вас!
Участие в семинаре бесплатное, просьба для регистрации направить письмо по адресу s.sosunova@trinitygroup.ru.
Читать дальше ...среда, 29 сентября 2010 г.
HDS: новый герой
Вчера случилось то, чего все уже давно ждали. Как мы все знаем, SAS диски крепко обосновались в системах хранения начального и среднего класса, но оставался последний оплот дисков с интерфейсом Fibre Channel – системы Hi-End.  Но вчера и этот бастион пал – HDS анонсировали новый флагман Hi-End класса VSP (Virtual Storage Platform). И конечно же, смена интерфейса бэкэнда вовсе не является основной особенностью новой системы. Сменилось многое. Да по большому счету, можно сказать что сменилось практически всё (ну разве что кроме преемственности функционала). Попробую хотя бы частично пробежаться по списку:
Но вчера и этот бастион пал – HDS анонсировали новый флагман Hi-End класса VSP (Virtual Storage Platform). И конечно же, смена интерфейса бэкэнда вовсе не является основной особенностью новой системы. Сменилось многое. Да по большому счету, можно сказать что сменилось практически всё (ну разве что кроме преемственности функционала). Попробую хотя бы частично пробежаться по списку:
 Но вчера и этот бастион пал – HDS анонсировали новый флагман Hi-End класса VSP (Virtual Storage Platform). И конечно же, смена интерфейса бэкэнда вовсе не является основной особенностью новой системы. Сменилось многое. Да по большому счету, можно сказать что сменилось практически всё (ну разве что кроме преемственности функционала). Попробую хотя бы частично пробежаться по списку:
Но вчера и этот бастион пал – HDS анонсировали новый флагман Hi-End класса VSP (Virtual Storage Platform). И конечно же, смена интерфейса бэкэнда вовсе не является основной особенностью новой системы. Сменилось многое. Да по большому счету, можно сказать что сменилось практически всё (ну разве что кроме преемственности функционала). Попробую хотя бы частично пробежаться по списку:-
(сразу бросается в глаза) шкаф стал стандартным (19’’), хотя конечно в “свой” шкаф систему не поставить -
Дисков стало больше (до 2048шт). В ряд можно поставить 6 шкафов, в 2х из них контроллерный модуль займет 14U и еще 26 юнитов останется под диски, а 4 шкафа – только для дисков. 2048 дисков можно поставить только с использованием 2.5’’ SFF дисков (да-да, поддерживаются и такие!). Если используются 3.5’’ диски, то максимальная набивка уже только 1280 дисков. -
Теперьможнонужно использовать однофазное питание(на USP-V и более ранних требовалось 3 фазы) -
Поддержка до 96 портов FCoE (правда немного позднее), а заодно отказались от поддержки ESCON интерфейса (кто-то его еще использует?). -
Максимальный объем кэша увеличен до 1ТБ(!) -
Защита кэша посредством записи на флэшку, а значит уже не требуется такое огромное количество батарей, которое было привычным всем владельцам монолитных систем. -
Появилась нормальная поддержка SSD дисков (см. следующий пункт). -
Вместе с SSD появилась и технология автоматической миграции данных между уровнями хранения (Page Level Tiering). -
Анонсирована поддержка инициатив VMware в области хранения (VAAI). -
Поддержка VMotion Anyware посредством Hitachi Dinamic Link Manager. -
Поддержка шифрования на уровне BED (XTS-AES 256).
Уверен, что забыл еще про что-нибудь упомянуть. Но даже этот список показывает, что работа была проделана большая.
Основные изменения коснулись архитектуры системы, которая является уже пятым поколением. Из каких же частей состоит система?
VSP может состоять либо из одного контроллерного шасси (не контроллера, а именно шасси), либо из двух (в разных шкафах).
 Шасси соединяются по PCI-E (правда первого поколения) шине и образуют единый комплекс. Все компоненты внутри одного шасси также связаны через PCI-E. Связь обеспечивается посредством Grid Switch, коих может быть либо 2, либо 4 на одно шасси. “Мозгом” являются модули VSD (Virtual Storage Director) – именно они занимаются всей работой с томами, обеспечивают thin provisioning, tiering и т.д. В отличие от конкурентных решений, не требуется обеспечивать высокоскоростной линк между VSD – каждый том в данный момент времени может управляться только одним VSD. Уже никого не удивить наличием процессоров x86 внутри системы. И VSP не является исключением – выполнение задач общего назначения отданы именно процессорам Intel (quad core Xeon). Диски подключаются к BackEnd Director (BED), на каждом из которых по два порта 4lane SAS 6Gbit. Т.е. в максимальной набивке можно получить до 64х линков 6Gbit SAS (48GB/sec). Причем приобретать систему вместе с дисками (и соответственно BED модулями) вовсе не обязательно (ведь все помнят, что уже USP-V умеет виртуализировать внешние системы хранения) – можно использовать и имеющиеся СХД, подключая их через VSP. Хосты подключаются к модулям FrontEnd Director (FED), каждый из которых поддерживает до 12ти портов 8Gbit FC (или FICON). Позднее должны появиться 4х портовые FED модули FCoE. Вот здесь уже стандартными процессорами не обошлись и на помощь пришли специализированные двуядерные процессоры собственного производства Hitachi (data accelerator ASIC). Именно они занимаются непосредственной обработкой критических к латентности данных. Последним в списке значатся Data Cache Directors – модули с кэш памятью (до 4шт в шасси), каждый может иметь объем от 32 до 128ГБ. На каждом из модулей расположен flash SSD для хранения кэша при отключении питания. Кэш записи зеркалируется попарно между двумя модулями (прочитанные же блоки всегда кэшируются только в одном экземпляре). Еще одна особенность в организации памяти заключается в том как защищена служебная память в VSD модулях. Она уже не зеркалируется между директорами, как в прежних системах, но зато резервная копия всегда сохраняется в паре кэш модулей (это не зеркалирование, а именно резервная копия, оптимизированная для быстрого восстановления). А так как память в кэш модулях, в свою очередь, уже зеркалируется между ними, то получается троекратная защита служебных данных- бэкап на паре Cache Director + хранение на flash памяти (как и любая другая записываемая в кэш информация). Такой подход позволяет еще больше “развязать” VSD модули друг от друга. Физически в контроллерном шасси все модули, к которым могут подключаться кабели, выведены на заднюю сторону шкафа:
Шасси соединяются по PCI-E (правда первого поколения) шине и образуют единый комплекс. Все компоненты внутри одного шасси также связаны через PCI-E. Связь обеспечивается посредством Grid Switch, коих может быть либо 2, либо 4 на одно шасси. “Мозгом” являются модули VSD (Virtual Storage Director) – именно они занимаются всей работой с томами, обеспечивают thin provisioning, tiering и т.д. В отличие от конкурентных решений, не требуется обеспечивать высокоскоростной линк между VSD – каждый том в данный момент времени может управляться только одним VSD. Уже никого не удивить наличием процессоров x86 внутри системы. И VSP не является исключением – выполнение задач общего назначения отданы именно процессорам Intel (quad core Xeon). Диски подключаются к BackEnd Director (BED), на каждом из которых по два порта 4lane SAS 6Gbit. Т.е. в максимальной набивке можно получить до 64х линков 6Gbit SAS (48GB/sec). Причем приобретать систему вместе с дисками (и соответственно BED модулями) вовсе не обязательно (ведь все помнят, что уже USP-V умеет виртуализировать внешние системы хранения) – можно использовать и имеющиеся СХД, подключая их через VSP. Хосты подключаются к модулям FrontEnd Director (FED), каждый из которых поддерживает до 12ти портов 8Gbit FC (или FICON). Позднее должны появиться 4х портовые FED модули FCoE. Вот здесь уже стандартными процессорами не обошлись и на помощь пришли специализированные двуядерные процессоры собственного производства Hitachi (data accelerator ASIC). Именно они занимаются непосредственной обработкой критических к латентности данных. Последним в списке значатся Data Cache Directors – модули с кэш памятью (до 4шт в шасси), каждый может иметь объем от 32 до 128ГБ. На каждом из модулей расположен flash SSD для хранения кэша при отключении питания. Кэш записи зеркалируется попарно между двумя модулями (прочитанные же блоки всегда кэшируются только в одном экземпляре). Еще одна особенность в организации памяти заключается в том как защищена служебная память в VSD модулях. Она уже не зеркалируется между директорами, как в прежних системах, но зато резервная копия всегда сохраняется в паре кэш модулей (это не зеркалирование, а именно резервная копия, оптимизированная для быстрого восстановления). А так как память в кэш модулях, в свою очередь, уже зеркалируется между ними, то получается троекратная защита служебных данных- бэкап на паре Cache Director + хранение на flash памяти (как и любая другая записываемая в кэш информация). Такой подход позволяет еще больше “развязать” VSD модули друг от друга. Физически в контроллерном шасси все модули, к которым могут подключаться кабели, выведены на заднюю сторону шкафа: А с фронта можно получить доступ к VSD и кэш-модулям:
А с фронта можно получить доступ к VSD и кэш-модулям: Еще несколько слов про возможности динамической балансировки между уровнями хранения. Как и в случае thin provisioning, все операции по миграции делаются блоками в 42МБ. На мой взгляд – многовато. Уровни хранения можно выбирать любые – SSD/SAS/SATA или SAS/SATA или SSD/SATA. Но новые данные всегда сначала попадают на самый “быстрый” уровень хранения и, уже если они больше нужны, то постепенно сдвигаются на “медленный” уровень. В первом релизе page level tiering нет поддержки RADI10, также не поддерживаются внешние системы хранения – можно использовать только внутренние диски. Ну и поддержки mainframe тоже нет (планируется позднее).
Еще несколько слов про возможности динамической балансировки между уровнями хранения. Как и в случае thin provisioning, все операции по миграции делаются блоками в 42МБ. На мой взгляд – многовато. Уровни хранения можно выбирать любые – SSD/SAS/SATA или SAS/SATA или SSD/SATA. Но новые данные всегда сначала попадают на самый “быстрый” уровень хранения и, уже если они больше нужны, то постепенно сдвигаются на “медленный” уровень. В первом релизе page level tiering нет поддержки RADI10, также не поддерживаются внешние системы хранения – можно использовать только внутренние диски. Ну и поддержки mainframe тоже нет (планируется позднее). Ко всем этим замечательным возможностям добавляется еще переписанная система управления, которая стала заметно симпатичнее и функциональнее. Контроль доступа на базе ролей (RBAC) также поможет упростить жизнь при администрировании VSP.
Ну и справедливости ради, стоит заметить что HP (как OEM партнер HDS) также анонсировали систему StorageWorks P9500. Говорят, что принимали непосредственное участие в разработке. Как видно, постепенно названия продуктов сводятся к единой базе – уже есть P2000 и P4000, теперь P9500. И остался еще изрядный промежуток для продуктов 3PAR (поглощение на днях как раз завершилось).
Читать дальше ...
вторник, 17 августа 2010 г.
POWER7 наступает
Сегодня анонсируются новые серверы IBM на процессорах POWER7, вытесняя таким образом еще оставшиеся POWER6 модели. Линейка серверов POWER7, до сегодняшнего дня состоявшая из моделей 750/755/770 и 780 и лезвий PS70x, стала гораздо более стройна и логична. Лезвия и модели для HPC остались без изменений (там и так все хорошо), а вот в остальном сегменте новостей много.
Самый младший отдельностоящий сервер теперь будет Power 710 - односокетная 2U машина с вариантами процессоров 3.0ГГц / 4 ядра, 3.7ГГц / 6 ядер, 3.55ГГц / 8 ядер. Максимальный объем памяти – 64ГБ. Следующий за ним – двухсокетный сервер Power 730, тоже 2U. К вариантам процессоров добавлен 3.7ГГц 4х ядерный вариант (8 ядер в сервере), разумеется, и памяти можно поставить в два раза больше чем в 710ю модель – 128ГБ. Внешне эти две модели фактически не отличаются:


А вот на самом верху иерархии находится еще один новичок (если можно так сказать про гиганта) – Power 795, пришедший на смену славной 595ой модели.

Все серверы с процессорами Power7 поддерживают AIX, IBM i, SUSE Linux, Red Hat Linux, разделы с различными ОС могут как обычно работать параллельно на одной машине.
С учетом тех возможностей по виртуализации и консолидации, которые предоставляют все перечисленные машины, а также учитывая позиции остальных игроков на рынке UNIX систем, на мой взгляд стоит ждать роста доли IBM. Также не стоит забывать про начавшую активно развиваться поддержку СУБД DB2 в системе 1C:Предприятие – это также может дать существенный плюс в распространении серверов IBM Power.
Читать дальше ...пятница, 23 июля 2010 г.
Autovirt – новые возможности
К уже и без того впечатляющему функционалу AutoVirt появилось прибавление!
- Стала поддерживаться интеграция с NetApp SnapMirror:
можно как импортировать существующие настройки, так и создавать новые “зеркальные” пары. Кроме того, можно обеспечить автоматизированный или ручной failover через глобальное пространство имен AutoVirt. - Управление NetApp SnapLock:
- через функционал архивирования можно перемещать (на основе фильтров) файлы из любой файловой “шары” на том с включенным SnapLock.
- можно также импортировать настройки SnapLock и управлять опциями через GUI AutoVirt
Обе возможности должны быть весьма интересны владельцам систем хранения NetApp. Причем политики миграции данных на SnapLock том могут заметно упростить жизнь при планировании инфраструктуры. Далеко не все данные необходимо хранить неизменными, поэтому нужно каким-либо образом отправить на SnapLock том только определенные файлы и здесь серьезным подспорьем будет AutoVirt.
Читать дальше ...вторник, 20 июля 2010 г.
Что запомнить, а что забыть…
Помимо различных замечательных возможностей в работе с дисковыми устройствами, в версии vSphere 4.1 несколько изменилась и работа с оперативной памятью – появилась функция “Memory Compression” (сжатие страниц-кандидатов на попадание в своп), которая в определенных случаях может заметно помочь. Срабатывает она только в моменты “перенасыщения” памяти (over-commintment), поэтому на нормальную работу (мы же не будем специально загонять себя в такой режим?!) она не влияет, но как только появляется потребность сбросить страницы в своп на диске (рис b), начинает работать memory compression. Обоснование ее использования состоит в том, что процедура распаковки сжатой страницы из специально отведенного пула (рис c) займет гораздо меньше времени, чем “вытаскивание” ее из своп-файла на диске:

Подробности можно прочитать (с картинками, но без диалогов) в соответствующем обновленном документе от VMware. Там же есть и некоторые результаты тестов. В частности, показано как memory compression улучшает результат Swingbench (вернее снижает степень его деградации при перенасыщении памяти):

пятница, 16 июля 2010 г.
Чем померить виртуализацию?
Попытки сделать стандартный тест (бенчмарк) для систем виртуализации делались уже давно, но единого общего знаменателя я не встречал. VMware использует свои попугаи, остальные стараются как-то выкручиваться. Плюс были попытки создать независимые бенчмарки, но как-то пока никто не прижился.
Но вот 14 июля сего года небезызвестный SPEC запустил свой бенчмарк для виртуализации - SPECvirt_sc2010. Основан он на целом ряде других тестах SPEC – SPECweb2005, SPECjAppserver2004, SPECmail2008. В виртуальной среде создается “инфраструктура” из нескольких VM, в которых и выполняется набор тестов:
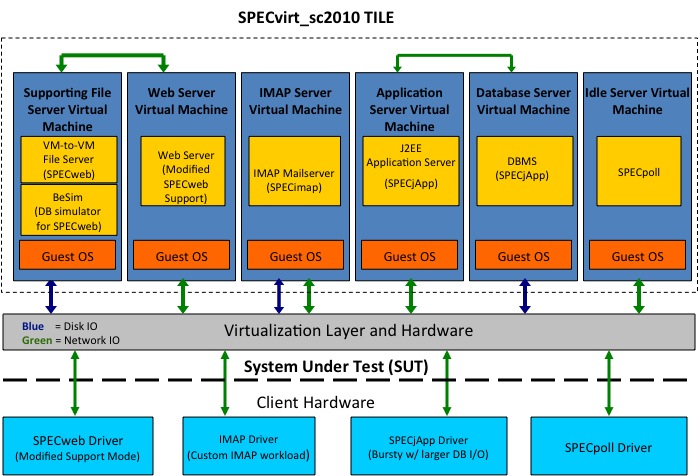
Таких “инфраструктур” (Tile) на одном сервере может быть запущено несколько и как раз это показывает насколько хороша масштабируемость:

Результаты бенчмарка отображаются в виде <Overall_Score> @ <6*Number_of_Tiles> (т.е. после символа @ идет суммарное число VM, запущенных на хосте).
Подробнее про схему бенчмарка можно прочитать здесь.
Хочется верить, что выход в свет SPECvirt_sc2010 позволит немного более предметно проводить сравнения и гипервизоров, и железа.
На текущий момент в тестах наметился уверенный лидер – IBM с сервером x3650M3 и KVM в качестве гипервизора (результат 1169 @ 72). Во многом правда это лидерство обеспечено тем, что на сегодня это и единственный опубликованный результат :)
Читать дальше ...пятница, 9 июля 2010 г.
Сказка перед выходными
История придуманная и любые совпадения с реальными персонажами являются случайными (хотя и вполне вероятными).
Жил да был системный администратор, работал себе в небольшой компании, серверов у него в услужении было всего ничего – ну пусть будет 4 штуки, скажем. На серверах все стандартно, везде Windows Server установлен да и приложения на нем всякие работают – и контроллер домена, и файловый сервер, и почта, и SQL тоже был.
 Жил бы наш админ, да и горя бы не знал, только как случись какая неполадка в его хозяйстве, так сразу его под белы рученьки на ковер к начальству ведут и ругают на чем свет стоит. А он, бедный, только руками разводит да слезно просит бюджет увеличить, чтобы большую СХД купить – без нее никак у него не получится все задачи в виртуальную инфраструктуру перевести, обеспечив тем самым большую отказоустойчивость. Начальство же ему в ответ, хмуря брови - “Нет! Тебе лишь бы деньги казенные в расход пустить! Мы вон тебе серверов купили отличных уже недавно! А нагрузка, сам говоришь, процентов 10 от силы. Да как у тебя язык-то поворачивается о таком просить?! Кризис же на дворе! Поди прочь, с глаз долой и сделай срочно, чтобы все работало!”.
Жил бы наш админ, да и горя бы не знал, только как случись какая неполадка в его хозяйстве, так сразу его под белы рученьки на ковер к начальству ведут и ругают на чем свет стоит. А он, бедный, только руками разводит да слезно просит бюджет увеличить, чтобы большую СХД купить – без нее никак у него не получится все задачи в виртуальную инфраструктуру перевести, обеспечив тем самым большую отказоустойчивость. Начальство же ему в ответ, хмуря брови - “Нет! Тебе лишь бы деньги казенные в расход пустить! Мы вон тебе серверов купили отличных уже недавно! А нагрузка, сам говоришь, процентов 10 от силы. Да как у тебя язык-то поворачивается о таком просить?! Кризис же на дворе! Поди прочь, с глаз долой и сделай срочно, чтобы все работало!”. И после таких разговоров шел обычно админ, понурив голову, к себе в кабинет и думку думал, но решение никак не приходило. Он уже и прикинул, какая производительность для текущих задач нужна – действительно, если Hyper-V использовать, то и пары физических серверов хватит. Но все равно – нужен внешний сторадж, чтобы хранить данные виртуальных машин. Можно конечно на “лишнем” сервере сделать iSCSI target (благо вариантов таких полно сейчас, даже и бесплатных). Но что будет, если это сервер “рухнет”?! Тогда уж сразу можно заявление на стол, а голову в петлю. Резервные копии на второй сервер немного подсластят жизнь, да только остановка сервисов при сбое все равно будет слишком долгая. Как же быть?
И вдруг вспомнил админ, что совсем недавно читал в каком-то блоге :) про Sanbolic Melio 2010. Есть же там и специальная редакция для Hyper-V, цена которой начальство ну никак не расстроит! И поддержка iSCSI есть, и кластерная файловая система все проблемы с CSV томами снимет. Так может быть можно и два iSCSI хранилища в “зеркало” объединить, чтобы защититься от сбоев? А ведь и правда можно (в DataCenter версии Melio Suite)! Тут уж и работа закипела, освободил админ два сервера, настроил на внутренних дисках RAIDы, установил iSCSI target, настроил все. Поставил на серверы с Hyper-V Sanbolic Melio 2010 (покупать сразу не решился, поэтому получил сначала демо-версию, которая по функционалу от оплачиваемой и не отличается ничем, кроме ограничения на срок использования). Создал зеркало, отформатировал диски – и все!
 После этого сбой любого из серверов Hyper-V приводил только к перезапуску виртуальных машин на “живом” сервере, а если использовать DataCenter редакцию Melio, то и сбой сервера iSCSI вообще никак на доступности сервисов не отражается – вторая половина зеркала берет всю нагрузку на себя.
После этого сбой любого из серверов Hyper-V приводил только к перезапуску виртуальных машин на “живом” сервере, а если использовать DataCenter редакцию Melio, то и сбой сервера iSCSI вообще никак на доступности сервисов не отражается – вторая половина зеркала берет всю нагрузку на себя. И вот тут-то админ и понял, что значит завоевать уважение и благосклонность начальства – бюджет решения был минимизирован, имеющееся оборудование было полностью задействовано, отказоустойчивость повысилась многократно. Теперь можно и в отпуск отпроситься, не опасаясь что через два дня срочно вызовут, да и обругают за то что ничего не работает.
Вот такая вот сказка получилась. Правдивая? По моему мнению - более чем!
Читать дальше ...
среда, 7 июля 2010 г.
SAS 2.0 6G со всех сторон
Последний рубеж взят – для x86 серверов IBM появился контроллер ServeRAID M5025. Теперь SAS 2.0 6Gbps можно использовать везде – и внутри сервера, и во внешних СХД, и в JBOD. Последний вариант и стал возможен благодаря этому контроллеру. Сами JBOD доступны с момента анонса DS3500: это EXP3512 и EXP3524, а теперь есть и RAID контроллер с внешними портами:
В комплекте, как и у младшего брата (M5015, у которого порты смотрят внутрь), есть батарейка. Кратко по характеристикам и возможностям:
- Контроллер построен на базе чипа LSI SAS2108 (RAID on Chip)
- 512МБ кэш-памяти на борту
- Поддерживается подключение до 240 дисков (до 9ти шасси с дисками на порт)
- Можно создать до 64 томов (LUN)
- Размер одного LUN ограничен 64ТБ
- Одновременное использование SAS и SATA дисков поддерживается, но смешивать диски в одном массиве нельзя.
- Стандартно поддерживается RAID 0, 1, 10, 5 и 50 (уровни 6 и 60 становятся доступны после покупки M5000 Advanced Feature Key)
ServeRAID M5025 это фактически копия LSI MegaRAID SAS 9280-8e, так что остальную информацию можно посмотреть на страничке оригинала.
Читать дальше ...вторник, 6 июля 2010 г.
Как обеспечить высокую доступность XenDesktop?
Citrix XenDesktop активно набирает популярность как решение для виртуализации десктопов (VDI). Не удивительно, что если мы принимаем решение перевести сотню (а то и не одну) пользователей в виртуальную среду, отказоустойчивость решения должна быть на высоте – потери от возможной остановки существенно выше, чем поломка одного ПК в офисе. При развертывании XenDesktop активно используется Citrix Provisioning Services (PVS) и высокая доступность этой компоненты является критичной для всего решения. Существует целый ряд возможностей по защите PVS:
- репликация
- LUN в режиме “только чтение”
- общий доступ посредством CIFS/NFS (общие папки на серверах Windows, NAS устройства)
Однако, все эти решения имеют довольно существенные недостатки:
- Репликация, во-первых, требует значительных дополнительных работ по администрированию. Во-вторых, репликация не обеспечивает высокую доступность базы данных PVS (а ведь она также необходима!). Невозможно также консолидировать файлы с write cache – его придется всегда хранить локально. Наконец, в таком режиме коэффициент полезного использования дискового пространства крайне мал из-за многократного дублирования информации.
- Использование LUN в режиме “только чтение” позволяет повысить утилизацию дисковых ресурсов, но администрирование такого решения становится еще более нетривиальной задачей – любое внесение изменений потребует перевода LUN в режим Managed Read-Only и, как следствие, в это время доступ к LUN будет иметь только один из серверов PVS. Но по-прежнему для обеспечения высокой доступности базы данных потребуется отдельное решение.
- Использование CIFS/NFS является наиболее простым и функциональным вариантом, однако узким местом может стать ограниченная производительность и масштабируемость. Кроме того это решение, как и уже упомянутые, не обеспечивает отказоустойчивость базы данных PVS.
Но есть и еще одно решение, которое позволит решить практически все проблемы, характерные для вышеперечисленных вариантов – совместное использование CIFS (на базе Windows Server) и Sabolic Melio Suite. Какие же преимущества у данного подхода?
- Как и в случае с использованием только CIFS, любой из серверов PVS имеет доступ к данным как на чтение, так и на запись.
- Файлы write cache можно хранить на общем ресурсе.
- Sanbolic Melio 2010 обеспечивает более высокую производительность, так как теперь можно просто увеличить число файловых серверов – так как они работают параллельно, производительность системы будет фактически ограничена только производительностью дисковой подсистемы. А благодаря использованию “страйпинга” можно увеличивать производительность и еще больше. Зеркалирование позволит, при необходимости, повысить отказоустойчивость, защитившись от сбоя в т.ч. и целой СХД.
- Возможность динамического расширения дискового пространства без какого-либо влияния на работу пользователей является еще одним огромным плюсом – любой администратор понимает, что выделить “окно” для обслуживания становится с ростом пользователей все сложнее и сложнее.
- Помимо обеспечения высокой доступности дисковых ресурсов, Melio 2010 предоставляет уникальное решение (AppCluster) для обеспечения высокой доступности сервера SQL (базы данных PVS).
- Поддержка VSS решает упрощает резервное копирование и позволяет быстро восстановить систему после сбоя.
В разговорах я часто слышу примерно такие слова “XenDesktop? Очень интересное решение, мы думали, но обеспечить отказоустойчивость для PVS сложно, поэтому пока отказались”.
Как видите, решение есть! Да, конечно, оно стоит денег, но, во-первых, не так уж и много, а, во-вторых, это решение замечательно работает и снимает существующие ограничения других подходов!
Читать дальше ...IBM и расширенная гарантия
В июле сего года IBM открыл новый склад запчастей в г.Хабаровск. Как следствие, теперь можно приобрести расширенный сервис (а главное пользоваться), включающий гарантированное время восстановления оборудования уже в 14 городах России.
Для удобства нанес их на карту. Так что если Вы приобретаете оборудование IBM, которое будет работать именно в этих городах - задумайтесь на предмет покупки также и расширенной гарантии. Это позволит существенно сократить возможные простои в случае каких-либо гарантийных проблем.
Для остальных городов есть также довольно привлекательный вариант по расширению гарантии - отправка запчастей на следующий рабочий день. Такие пакеты конечно несколько дешевле тех, что гарантируют восстановление оборудования. А в городах, где есть склады запчастей, (см. карту) обеспечивается не просто отправка запчасти заказчику, но и выезд специалиста с этими запчастями (в пределах 100км).
Просмотреть IBM FixPac на карте большего размера
четверг, 27 мая 2010 г.
ScaleMP покоряет новые горизонты
Задача объединения нескольких серверов в один гораздо более мощный замечательно решается при помощи vSMP Foundation от компании ScaleMP – про это я некоторое время назад уже писал. Если вкратце, то используя стандартные x86 серверы, infiniband и гипервизор от ScaleMP можно получить сервер поддерживающий до 32х сокетов и до 4ТБ памяти. Интересно, что конфигурации машин, входящих в кластер могут отличаться – если процессорных ресурсов нужно не слишком много, то часть машин может быть с “быстрыми” процессорами, а остальные с минимальными возможными и предоставлять в качестве общего ресурса только оперативную память. Однако у vSMP Foundation есть и некоторые особенности, про которые необходимо помнить. Во-первых, установить на такой сервер можно далеко не всякую операционную систему – на текущий момент это может быть только Linux, причем для оптимальной производительности нужно либо пересобрать ядро, либо использовать вариант от ScaleMP (они есть в частности для RedHat). Во-вторых, vSMP предназначен именно для объединения ресурсов. То есть вместо двух (трех, четырех…) серверов мы получаем один, но более мощный, соответственно, выход из строя одной из машин вызовет остановку/перезагрузку всего комплекса. Кроме того, так как речь идет про объединение, то на один комплекс vSMP нельзя поставить несколько операционных систем (т.е. выделить полторы машины для одной задачи, а еще две с половиной для другой). Но последний пункт был верен только до недавнего момента! Буквально на днях была анонсирована технология VM-on-VM. Что это такое? Очень просто - фактически заявлено о начале поддержки виртуализации серверов на базе KVM и Xen в кластере vSMP Foundation. Это дает возможность существенно снизить цену “железной составляющей” на базе 4-8ми сокетных систем. А это, в свою очередь, позволит консолидировать (виртуализовать) более требовательные к ресурсам сервисы без использования дорогостоящего оборудования. Декларируется также упрощение управления, впрочем, здесь я не испытываю особенного энтузиазма – самим vSPM тоже нужно управлять, поэтому снижение затрат на управление будет не самым важным аргументом. По крайней мере не таким важным, как цена решения.

Ссылки по теме:
Объединяй и властвуй!
ScaleMP
среда, 19 мая 2010 г.
Глобальное пространство имен файлов (4/4)
Сегодня заключительная (четвертая) часть серии заметок про управление файловыми серверами. Речь пойдет уже не столько про глобальное пространство имен файлов, а про дополнительные возможности, возникающие в результате его внедрения.
Часть 1-ая
Часть 2-ая
Часть 3-я
Политики управления данными.
Основной плюс AutoVirt - это возможность не просто создать глобальное пространство имен, но и обеспечить управление неструктурированными данными на основе предопределенных администратором политик.
Представьте, что Вам нужно перенести все файловые ресурсы с нескольких старых серверов на новый. А если все эти ресурсы активно используются? А если нужно сохранить ссылки на ресурсы неизменными, а DFS не используется? А если нужно не только перенести данные, но старые серверы вообще вывести из обслуживания, либо использовать для других нужд? Любое из этих "если" добавляет головную боль. Вот здесь преимущества от использования AutoVirt и глобальной системы имен файлов выходит на первый план! Нам достаточно добавить новую политику (Migration) через web-интерфейс, выбрать что и куда мы хотим перенести, задать время и подождать окончания процесса. Все! Больше ничего делать не нужно. Пользователи не заметят вообще ничего. Более того, если исходный файловый ресурс имеет громадный объем и сильно нагружен, мы можем задать предварительное копирование данных в удобный нам интервал времени (вероятно это будет ночь). В это время файлы будут постепенно копироваться на новый ресурс, тогда в момент фактической миграции потребуется скопировать только изменившиеся с момента предварительной синхронизации файлы и переключить пользователей на новый сервер (еще раз отмечу, что все это делается без участия администратора). Важно, что корректно будет произведена не только миграция самих файлов, но и всех прав доступа (ACL). Если необходимо осуществить миграцию настолько большого объема данных, что два стандартных Data Engine (про них подробнее написано во второй части) не справляются с поставленной задачей за приемлемое время, то достаточно просто добавить нужное количество серверов на время миграции (никаких дополнительных лицензий для этого не потребуется). Так как DataEngine работают независимо, то рост их числа практически линейно увеличит скорость миграции (если конечно сам файловый сервер справляется с такой нагрузкой).
Но миграцией возможности AutoVirt не ограничиваются - список политик включает в себя:
- Measure - это просто отчет о том как используется дисковое пространство (число файлов, их объем и т.п.). Позволяет оценить требования к ресурсам для дальнейших операций по миграции/репликации.
- Copy - копирование данных. Отличается от миграции тем, что не происходит переключение пользователей на новый ресурс. Зато можно отфильтровывать файлы по типу. Это довольно ограниченная по возможностям политика, так что если нужны дополнительные функции следует использовать Replication.
- Replication - пожалуй, самая "продвинутая" по возможностям опция. Именно она при миграции с DFS будет альтернативой использованию DFS-R.
Несколько слов подробнее про каждый из типов репликации:
Клонирование "один источник - один клон" предназначено для обеспечения отказоустойчивости. Данные "мастера" реплицируются на удаленную площадку, а в случае сбоя происходит перенаправление клиентов на реплику.
Отношение "один источник - много клонов" удобно для организации с множеством филиалов, в каждым из которых необходимо обеспечить доступность однотипных материалов в режиме чтения. Это позволит сократить расходы и снизить загрузку каналов связи. В случае сбоя, запросы будут перенаправлены на ближайший к клиенту сервер.
Если в организации много филиалов и стоит задача централизованно хранить данные, то замечательно подойдет третий вариант - "много источников - один клон". В случае сбоя на удаленной площадке, failover будет индивидуальным для каждого филиала (т.е. отсутствует влияние на остальных - они продолжат работу в обычном режиме).
Во всех описанных вариантах, для восстановления после сбоя следует использовать миграцию, чтобы произвести обратную синхронизацию данных и осуществить переключение пользователей на исходный ресурс. -
И, наконец, последняя политика Deletion - удаляет все исходные данные после успешной миграции. Политика простая, но применяется крайне редко (ввиду очевидного риска).

Для всех политик можно задать так называемый "тихий час", когда никакие действия производиться не могут - например в периоды максимальной загрузки системы. Это позволяет избежать излишней нагрузки и обеспечить максимально комфортную работу пользователей.
Простая интеграция в инфраструктуру, весьма продвинутые возможности по обеспечению высокой доступности (как самой глобальной системы имен, так и непосредственно файловых ресурсов), набор удобных политик для управлению ресурсами, полная поддержка ACL при любых миграциях/репликациях, а также интуитивно понятный интерфейс - все это делает продукт по настоящему уникальным.
Наверное лишним будет упоминать, что Тринити является партнером AutoVirt в России. Так что куда обращаться за дополнительной информацией, а также по вопросу пилотных инсталляций Вы наверняка догадываетесь. :)
А для тех, кто продолжает использовать в своей инфраструктуре Brocade StorageX (и имеет оплаченную поддержку), есть очень заманчивое предложение – до 30 июня 2010г. действует специальная акция со скидками при замене лицензий StorageX на AutoVirt.
Читать дальше ...Управлять СХД – просто!
Если используется одна система хранения, то управлять ей конечно несложно!
А вот если их три или и того побольше? — Как осуществлять мониторинг систем, чтобы не допускать ситуации, когда нагрузка становится фактически предельной, а жизнь пользователей становиться безрадостной?
Если у вас используются системы IBM, то существует такой замечательный продукт как Tivoli Storage Productivity Center (TPC).
Tivoli Storage Productivity Center (TPC)
По сути это даже не один продукт, а несколько разных: TPC Basic Edition, TPC for Data, TPC for Disk, TPC for Replication, TPC Standard Edition.
TPC for Disk как раз позволяет следить за состоянием СХД и их производительностью, а также получать алерты и всевозможные отчеты.
Проблема в том, что для СХД начального и среднего уровня цена TPC for Disk была до недавнего момента явно высокая (учитывая тот факт, что лицензируется весь объем дискового пространства).
И вот, совсем недавно (14-го мая) была анонсирована еще одна версия: TPC for Disk MidRange Edition (TPC for Disk MRE).
Отличие ее от “старшего” брата состоит в том, что, во-первых, поддерживаются только системы DS3000/4000/5000, а во-вторых, (и это, на мой взгляд, основное) лицензирование осуществляется по устройствам. Т.е. фактически нужно просто сложить количество контроллерных и дисковых полок и умножить результат на стоимость лицензии.
Цена лицензии
В большинстве случаев цена получается ниже примерно в два раза (а если используются SATA диски большого объема, то разница в цене может быть и в несколько раз). В результате, можно централизованно (с интервалом до 5-ти минут) получать следующие данные:
- производительность контроллеров (число операций ввода-ввывода)
- производительность контроллеров (скорость передачи данных)
- процент попадания в кэш
- производительность отдельных портов контроллеров
Качество предоставления сервисов
Проактивный мониторинг состояния и производительности позволяет существенно упростить управление инфраструктурой, а главное – дает возможность повысить качество предоставления сервисов.

Читать дальше ...
Пара слов про IBM DS3500 (DS3512/DS3524)
Официальный анонс прошел, системы начнут отгружаться 15го июня, всю информацию конечно можно найти на сайте IBM, но если не хочется читать и искать,то вот немного информации:
- Две базовых модели – на 12 3.5” диска (DS3512) и на 24 2.5” диска (DS3524), полки расширения также на 12x3.5” и 24x2.5” (EXP3512 и EXP3524 соответственно).
- Максимум на текущий момент поддерживается 96 дисков SAS, т.е. можно получить до 192ТБ на “медленных” дисках.
- Поддерживаются диски с шифрованием (только 600ГБ SAS).
- Двухконтроллерная система в “базе” имеет 4 SAS порта для подключения к хостам, кроме того, можно к каждому контроллеру добавить интерфейсную плату либо с 2мя портами SAS, либо с 4мя портами FC 8Gbit, либо с 4мя портами iSCSI 1Gbit. Выбор по интерфейсам получается такой: 4xSAS, 8xSAS, 4xSAS + 8xFC, 4xSAS + 8xiSCSI. Мне лично немного жаль, что нет варианта iSCSI + FC, но видимо маркетологи посчитали иначе :)
- Производительность из кэша – до 200тыс IOPs (при включенной опции Turbo Performance) и до 40000/12500 IOPs чтение/запись с дисков. Линейная производительность заявлена 4000/2600 MB/s для чтения/записи. Кэш 1 или 2ГБ на контроллер.
- Контроллеры “общаются” друг с другом через интерфейс PCI-E 2.0 x8, что дает пропускную способность 4ГБ/сек.
- RAID традиционно реализован аппаратно, поддерживается и RAID 6 (P+Q).
- Батарейка служит не для того, чтобы поддерживать состояние кэш-памяти при сбоях питания, а для того, чтобы сбросить содержимое кэша на флэшку. Это дает возможность держать систему выключенной долгое время без потери данных в кэше.
- Из новых возможностей – синхронное и асинхронное зеркалирование (Enahnced Remote Mirror) по FC.
- Поддерживается до 64х Storage Partitions (по-умолчанию 4), до 8 мгновенных снимков на том (64 на систему).
- К СХД можно подключать хосты под управлением Windows, Linux, VMware (все это в базе), а также, при покупке соответствующей лицензии, AIX/VIOS, Linux on Power и HP-UX.
- В Linux поддерживается Device Mapper, что избавляет от необходимости устанавливать MPP для нормальной работы.
Выглядят системы вот так (тыльная сторона показана для SAS+FC и SAS+SAS):




Что сказать в итоге? DS3500 производит очень и очень достойное впечатление. Во многом из-за того, что по производительности и функционалу догнали системы среднего уровня и, при этом, остались в ценовых рамках DS3000. Диски SATA поддерживать не стали, я думаю из-за того что не хотели придумывать мультиплексор для 6Gbps, впрочем не сильно-то и нужно, когда Seagate делает 2TB диски с SAS интерфейсом. Пока не увидел возможности делать remote mirror между DS3500 и DS4000/5000 – может быть невнимательно смотрел, а может быть сделают со временем. Если сделают – это будет еще одним огромным плюсом, но пока и так поживем :) С учетом того, что DS3000 прожили на рынке уже 3года, а актуальность так и не потеряли, думаю, что системы DS3500 ждет большое будущее.
Читать дальше ...вторник, 18 мая 2010 г.
Глобальное пространство имен файлов (3/4)
Очередная (третья) часть небольшой серии заметок про то как можно упростить управление файловыми серверами. Вчера было рассказано про отказоустойчивость и общую схему. Сегодня речь пойдет про две другие возможности:
"Прозрачное" внедрение в инфраструктуру.
Добавление файлового сервера под управление AutoVirt делается в два этапа:
- На первом происходит просто сканирование файловых ресурсов, а самому серверу присваивается новое, "виртуальное" имя. При этом, никаких изменений в инфраструктуре в этот момент вообще не происходит - сервер остается доступен всем клиентам. Все файлы на нем также доступны со своими привычными UNC именами. По-умолчанию, виртуальное имя сервера отличается от “настоящего” приставкой "av-", впрочем, его можно задать и совершенно произвольно (главное, чтобы другого сервера с таким именем не было).
Теперь ко всем ресурсам файлера можно также обращаться, используя не только привычное UNC имя, но и виртуальное имя сервера. На практике это конечно не нужно, но зато дает возможность убедиться в том, что сервер AutoVirt нормально функционирует и можно приступать ко второму этапу. На картинке видно, что у нас есть Dependent (зависимое) пространство имен - это означает, то ресурсы хотя и доступны через сервер AutoVirt, но они "привязаны" к физическому серверу и пока еще не могут быть перенесены с него на другой файлер.
- Для того, чтобы полностью виртуализировать файловый ресурс (например \\fileserver) и "отвязать" его от "железа", необходимо запустить так называемый процесс "Cutover". Физически он сводится к тому, что мы (под руководством AutoVirt) меняем имя сервера на новое, а запросы к изначальному имени перенаправляются с этого момента на сервер AutoVirt. Собственно это и есть единственный перерыв в обслуживании - смена имени сервера требует его обязательной перезагрузки. Все остальное время все ресурсы сервера доступны пользователям в полном объеме! Т.е. время простоя сервиса составляет всего несколько минут! Теперь любой запрос к \\fileserver будет происходить через AutoVirt, который переадресует его на нужный сервер (либо на оригинальный, либо же на любой другой сервер, если была осуществлена миграция данных).

После такой несложной процедуры нам становятся доступны все прелести глобального пространства имен! Мы можем запустить процесс миграции данных на другой сервер, мы можем настроить репликацию данных между серверами и много чего еще, но об этом ниже.
А как быть, если нам потребуется отказаться от AutoVirt (всем система хороша, но бюджет на нее выделили только на следующий год)? И это тоже очень просто - достаточно произвести еще один Cutover, чтобы вернуть все на круги своя. Правда здесь уже нужно быть осторожнее - если была осуществлена миграция данных, процедура не столь тривиальна (иначе данные перестанут быть доступны по привычным UNC именам).
Поддержка DFS.
В AutoVirt есть также и поддержка Microsoft DFS. Реализована она полностью аналогичным образом, что и виртуализация файловых серверов. Сначала DFS испортируется, а потом необходимо произвести переключение на AutoVirt. После этого DFS уже больше не используется, а весь функционал глобальной системы имен ложится на плечи AutoVirt. Важно помнить, что состояние DFS отображается на момент импорта и не синхронизируется повторно, в случае внесения каких-либо изменений в DFS. Поэтому если стоит задача перейти от DFS к AutoVirt, не следует это делать параллельно с активным редактированием DFS - либо одно, либо другое. 
Подробный рассказ о главных преимуществах AutoVirt ждите в заключительной части. А пока (для затравки) сравнение возможностей с DFS:

Многопоточный RAID
IBM анонсировали новый RAID контроллер, предназначенный специально для SSD. В отличие от остальных, представленных сейчас в портфеле IBM контроллеров, этот сделан не компанией LSI, а совместно с PMC-Sierra. Так как ServeRAID B5015 предназначен исключительно для SSD, то и выбор уровней RAID довольно скромный – только RAID1 и RAID5, создать можно до 4х логических дисков (LUN) на контроллер. Максимум можно подключить до 8ми дисков SAS 2.0 6Gb/s (замечательно укладывается в концепцию exFlash для серверов IBM x3850X5/x3950X5). Сердце контроллера – три ядра MIPS с поддержкой многопоточности. В стеке maxRAID активно используется эта самая многопоточность для увеличения производительности по сравнению с имеющимися на рынке решениями. Кэша нет, а следовательно нет и необходимости в батарейке.

понедельник, 17 мая 2010 г.
Глобальное пространство имен файлов (2/4)
Это продолжение ранее начатой короткой серии заметок про управление файловыми серверами.
Так какие же есть альтернативные (предлагаемому Microsoft DFS) решения, чтобы удобно, просто и по возможности прозрачно для существующей инфраструктуры получить глобальное пространство имен? Рассказ пойдет о продукте компании AutoVirt. Первое, что бросается в глаза, - это не надстройка и не дополнение к Microsoft DFS. AutoVirt является совершенно самостоятельным решением и для его работы не требуется ни DFS, ни DFS-R - нужен только домен и конечно сами файловые серверы. Какие положительные качества решения можно выделить:
- отказоустойчивость "by design"
- прозрачное внедрение в инфраструктуру без необходимости что либо менять у пользователей
- поддержка DFS
- различные политики, обеспечивающие управление данными (миграция, репликация и т.п.)
Сначала немного остановимся на принципах работы, а затем я постараюсь подробнее описать каждую из "особенностей" AutoVirt.
Реализация глобальной системы имен основана на перенаправлении DNS запросов. Обычно, при обращении к папке на сервере, когда мы набираем \\A\myshare, сначала идет запрос к серверу DNS, который нам возвращает IP адрес сервера "A". А уже потом мы с этого файл-сервера получаем необходимые нам данные:


Отказоустойчивость и схема работы.
Совершенно очевидно, что для обеспечения нормальной работы пользователей необходима высокая доступность Global Namespace (глобального пространства имен). AutoVirt имеет встроенные возможности кластеризации (т.е. нет никакой необходимости ни настраивать Microsoft Cluster, ни платить за Enterprise лицензию Windows Server). Более того, настоятельно рекомендуется развернуть сразу два сервера AutoVirt в кластере. Настройка кластеризации происходит автоматически, при установке ПО - ничего для этого делать дополнительно не нужно. Полностью поддерживается установка в виртуальной инфраструктуре, более того, в большинстве случаев рекомендуется изначально идти именно по такому пути (по крайней мере на сравнительно небольших инсталляциях).
Концептуально схема AutiVirt выглядит так:

Управление AutoVirt'ом осуществляется через простую и интуитивно понятную WEB-консоль, никакого дополнительного ПО (кроме браузера с поддержкой SilverLight) администратору не требуется:

Про остальные преимущества и возможности AutoVirt в плане прозрачной интеграции в уже имеющуюся инфраструктуру рассказ будет продолжен завтра.
Читать дальше ...
Подписаться на:
Сообщения (Atom)











